반응형
SMALL
Introduction
• 대부분의 존재하는 인스턴스는 솔루션을 메트릭 러닝을 이용하여 이미지를 벡터로 변환하여 학습한다.
• 그리고 최근까지 많은 작업들은 이미지 검색을 위해 분류 모델을 사용한다.
• 또한 트리플렛로스는 대부분 넓은 범위를 접근하기 위해 사용된다.
• 하지만 트리플렛 로스는 여러 작업에서 지적된 문제점을 갖고 있다.
문제점

• 하드 네거티브 샘플링은 하나의 배치에 정보를 제공하는 트리플렛만 포함하는 트레이닝 배치들을 생성하는데 있어서 지배적인 접근방법이지만, 이는 로컬 최소값이 좋지 않아 모델이 최고의 성능을 내는데 방해가 될 수 있다.
• 하드 네거티브 샘플링은 배치에 모든 샘플 사이의 거리를 계산해야 하므로 계산 비용이 많이 든다.
• 트리플렛 로스는 하드 네거티브 샘플링과 point-to-point Loss 특성으로 노이즈 레이블이 발생하기 쉽다.
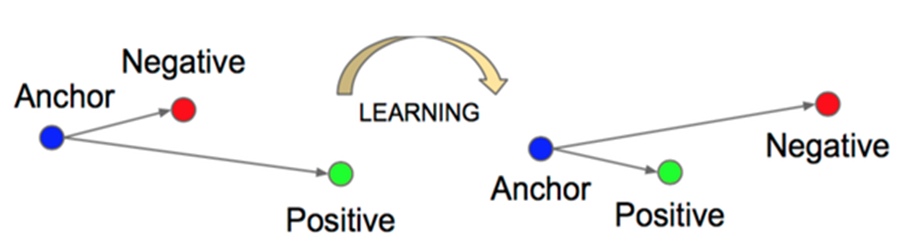
• Triplet Loss 의 point-to-point 특성으로 인한 문제를 해결하기 위해 Point-to-set / Point-to-centroid 공식에 대한 변경이 제안된다.
주요 이점
• 이상값 및 노이즈 라벨들에 대한 더 높은 견고함
• 빠른 트레이닝
• point-to-point triplet loss 보다 비슷하거나 더 나은 성능
추가 사항
• 훈련과 추론 모두에 중심 기반 접근 방식을 사용
• 패션 검색 및 사람 재 식별에 적용할 것을 제안
Centroid Triplet Loss
• 기존 Triplet Loss는 앵커 이미지 A, 포지티브(동일 클래스) P, 다른 클래스 N 네거티브 예제에서 작동한다.
• 기존의 목표는 A - P 사이의 거리를 최소화하며 N 샘플은 멀리 밀어내는 것이다.
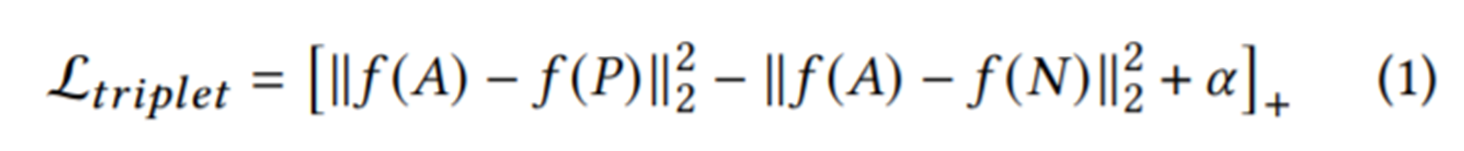
• 원래의 공식에서 [z] += max(z, 0), f는 학습 단계의 임베딩 함수, a는 마진

• CTL(Centroid Triplet Loss) 는 앵커 이미지 A의 거리를 포지티브 및 네거티브 인스턴스와 비교하는 대신 A와 앵커와 동일한 클래스 또는 다른 클래스를 나타내는 Cp와 Cn 사이의 거리를 측정한다.
Aggregating item representations

• 훈련 단계에서 각 미니 배치에는 M 개의 샘플이 있는 P, 각 개별 항목 클래스가 포함되어 배치 사이즈가 M x P 입니다.
• Sk가 미니 배치 클래스 k에 대한 샘플로 세트를 표시한다.
• 효과적인 훈련을 위해 Sk의 각 샘플은 쿼리 qk로 사용되고 나머지 M-1 샘플은 중심 Ckp를 구축하는데 사용된다.
• f는 이미지를 인코딩하는 신경망이다.

• 평가 동안 쿼리 세트 Q에서 이미지가 제공되고 검색이 발생하기 전 각 클래스 k에 대한 중심이 미리 계산된다.
• 이러한 중심을 구성하기 위해 k 클래스에 대해 갤러리 세트 Gk의 모든 임베딩을 사용한다.

• 앞서 설명한 중심 계산과 CTL을 적용한다.
• 이미지를 전달하는데 있어서 3개의 개별 손실 함수가 계산된다.
• Center Loss, Triplet Loss (Centroid Triplet Loss), Classification Loss
• 추론을 위한 중심은 원본 모델과의 일관성을 위해 배치 정규화 후에 계산된다.
Datasets
•DeepFashion : Fashion Retrieval
•Street2Shop: Fashion Retrieval
•Market1501: Person Re-ID
-> 정확도가 높았던 데이터 셋으로 테스트를 진행해보았다.
•DukeMTMC-reID : Person Re-ID
Detail
Loss Function
•세부분으로 구성된 손실 함수를 사용
•원시 임베딩에서 계산된 Triplet Loss
•보조 손실로 Center Loss
•배치 정규화 임베딩에서 계산된 Classification Loss
Retrieval procedure
• cosine similarity

Fashion Retrieval Results

* CE : Centriod 기반 평가
•두가지 모델을 평가한다.
•sota에 제시된 모델, ctl은 중심 기반 모델을 나타낸다.
•각 모델은 1) 이미지별 표준 인스턴스 수준 평가 2) 중심 기반 평가 를 했다.
•논문의 CTL 모델은 테스트된 모든 데이터 세트에서 대부분의 메트릭에서 나은 성능을 보인다.
Person ReID Results

• 우리는 패션 검색과 유사하게 다음 모델을 평가한다.
• sota는 reid의 최신 기술을 나타내고 ctl은 중심기반 모델을 나타낸다.
• 이미지 매칭에만 의존함에도 불구하고 중심 기반 검색은 두 데이터 세트의 모든 메트릭에서 거의 동일하거나 더 나은 결과를 달성했다.
Memory Usage and Inference Times

• 표준 이미지 기반 검색과 비교하여 중심 기반 방법의 메모리 및 계산 효율성을 테스트하기 위해 모든 테스트 데이터 세트를 평가하는 데 걸리는 시간과 모든 임베딩을 저장하는데 필요한 스토리지를 비교한다.
• 중심기반 접근 방식은 임베딩을 저장하는 데 필요한 검색 시간과 디스크 공간을 크게 줄입니다.
• 감소는 종종 클래스당 여러 이미지가 있기 때문에 중심으로 전체 객체 이미지 그룹을 나타내면 성공적인 검색에 필요한 벡터 수가 하나로 줄어듭니다.
Conclusion
• 인스턴스 검색 작업을 위한 새로운 손실 기능은 Centroid Triplet Loss 를 소개한다.
• 사람 재 식별 및 패션 검색이라는 두가지 다른 도메인의 4가지 데이터 세트에서 평가되고 SOTA를 달성했다.
• 정확도 향상 외에도 계산 속도를 높이고 메모리 요구사항을 낮추는 것으로 나타났다.
Code

• Triplet Loss
- N 과 P의 거리를 구하고 Loss에 반영하는 모습

• Center Loss
- 맨 마지막에 보면 dist들을 min, max를 지정해두고 더해서 배치 사이즈만큼 나눠서 로스를 구하는 모습

• 코사인 유사도
- 코사인 유사도를 통해서 쿼리와 갤러리의 유사도를 통해 거리로 표현하고 있는 모습
반응형
LIST
'[ study ]' 카테고리의 다른 글
| [Distributed System] 분산 시스템 - Middleware organization (1) | 2022.06.01 |
|---|---|
| [논문리뷰]Expressive Body Capture: 3D Hands, Face, and Body from a Single Image (0) | 2022.06.01 |
| [Distributed System]분산 시스템 - Architecture - Architectural styles - Application layering (0) | 2022.03.18 |
| [jinja] extends 사용하기 (0) | 2021.04.24 |
| [jinja] block과 if 조건문 같이 사용하기 (0) | 2021.04.24 |

